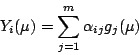The measured mass spectra may be denoted by ![]() , where
, where
![]() is the sample number, and
is the sample number, and ![]() is the mass number. Since
is the mass number. Since
![]() takes on only discrete values
takes on only discrete values
![]() , each
mass spectrum can be represented by a vector in a
, each
mass spectrum can be represented by a vector in a ![]() -dimensional
vector space,
-dimensional
vector space,
![]() . These are assumed to be made up
of linear combinations of the component spectra,
. These are assumed to be made up
of linear combinations of the component spectra,
The problem is analogous to that of curve resolution encountered, for example, in chromatography or spectrophotometry, where it has been treated with considerable success using the technique of principal component analysis. Lawton and Silvestre (1971), for example, have considered the case of two source components and have developed a method for computing two bands of curves, each containing one of the source components. The method of principal component analysis, however, runs into difficulties if the data are characterized by widely different experimental uncertainties. This is often the case with mass spectroscopic data. Even if the relative uncertainties in isotopic ratios are similar, the ratios can vary by orders of magnitude. As Anderson (1963) pointed out, the method of principal component analysis is justified only if the ratio of the ``uncertainty'' variance to the ``systematic,'' i.e. correlation, variance is the same for all components of the data. Nonconformity with this requirement may be remedied to some degree by rescaling the data according to their respective uncertainties. Here we abandon the method of principal component analysis for an alternative approach that is on a better statistical footing in that it takes full account of the estimated uncertainties of the data.
It is easily shown that data points consisting of linear combinations
of components according to Equation (1) must lie in
an ![]() -dimensional subspace of the full
-dimensional subspace of the full ![]() -dimensional vector
space. This subspace is defined by the simplex whose vertices are the
-dimensional vector
space. This subspace is defined by the simplex whose vertices are the
![]() distinct components. This paper deals with only the first step in
component resolution, namely the determination of the parameters of
this subspace. Furthermore, it considers only the simplest case, in
which
distinct components. This paper deals with only the first step in
component resolution, namely the determination of the parameters of
this subspace. Furthermore, it considers only the simplest case, in
which ![]() , that is, the number of components is the same as the
number of coordinates of the space (e.g. the number of isotopic
ratios measured in each sample). Thus for 2-dimensional data we seek
the equation of a straight line, for 3-dimensional data a plane, and
in general a hyperplane of dimension one less than the space in
which it is embedded. The general case of arbitrary
, that is, the number of components is the same as the
number of coordinates of the space (e.g. the number of isotopic
ratios measured in each sample). Thus for 2-dimensional data we seek
the equation of a straight line, for 3-dimensional data a plane, and
in general a hyperplane of dimension one less than the space in
which it is embedded. The general case of arbitrary ![]() is to
be dealt with in a future paper.
is to
be dealt with in a future paper.